L'optimisation des grands ensembles de données Odoo est une question très importante car, lorsque Odoo est utilisé par de grandes entreprises, cela implique que le système est utilisé de manière intensive et que cela s'accompagne d'une croissance des données très rapide et soutenue. Évidemment, les tables standard les plus impactées seront celles que nous appelons les tables "_lines", telles que :
-
ligne_commande_de_vente
-
ligne_mouvement_compte
-
ligne_mouvement_stock
Le problème
Pour évaluer l'impact de la croissance des données génériques sur ces tables, imaginons une entreprise standard avec 10 branches et 2 personnes comptables validant 100 factures chacune par jour ouvré. Soyons justes et fixons le nombre moyen de ligne_facture_de_vente par facture à 10 articles par facture. Les résultats seraient les suivants :
-
100 factures X 10 articles par facture = 1 000 lignes de factures.
-
1 000 lignes de factures généreront 1 000 lignes de produit + 100 lignes de taxe + 100 lignes de montant total de facture dans le Journal des Ventes si nous avons configuré ce dernier pour écrire des mouvements de compte PAR PRODUIT, ce qui est la seule bonne façon d'obtenir plus tard de bonnes valeurs de tableau de bord par compte ou par catégorie de produit etc... Quoi qu'il en soit, cela signifie 1 200 lignes_de_mouvement_de_compte par utilisateur par jour.
-
Multiplié par 2 utilisateurs, cela nous donne 2 400 entrées de ligne_de_mouvement_de_compte par branche par jour.
-
Multiplié par 10 branches, cela nous donne 24 000 entrées de ligne_de_mouvement_de_compte par entreprise par jour.
-
Multiplié par 25 jours ouverts, nous obtenons 24 000 X 25 = 600 000 lignes_de_mouvement_de_compte par mois.
-
Annuellement, nous obtenons 600 000 x 12 = 7 200 000.
Au-delà de 3 millions de lignes, vous commencerez à ressentir un impact important sur les performances.
Au-delà de 5 à 6 millions de lignes, vous serez fortement pénalisé. Bien sûr, cela dépend de votre matériel, de la technologie des disques, de la disponibilité du CPU, de la stratégie de mise en file d'attente….. mais en tout cas, dans notre cas présent, plus de mauvaises nouvelles arrivent :
-
7 200 000 entrées account_move_line représentent des factures purement validées….. mais cela signifie que la table sales_order_lines peut être 2 à 10 fois plus grande dans la même période car elle contient également des devis. Soyons justes et évaluons que vous convertissez 30 % de vos devis en ventes : votre table sales_order_line sera environ 3 fois plus grande : cela fait environ 21 000 000 d'entrées par an dont nous parlons.
-
Vous avez tout autant à entrer dans les tables des lignes de mouvement de stock.
-
Je ne parle même pas de MRP qui peut rendre des tables encore plus grandes avec des numéros de lot, etc… si ce client fait également de la production.
-
Je suppose qu'il s'agit d'un système MONO SOCIÉTÉ …. sinon, vous vous retrouverez avec des données de différentes entreprises dans les mêmes tables… Imaginez cela multiplié par 3 entreprises dans les mêmes tables !
-
Je suppose que vous avez un serveur dédié et des ressources dédiées par entreprise, mais ce n'est pas toujours le cas car beaucoup de gens mutualisent l'hébergement.
Maintenant, si nous considérons que vous avez environ 30 utilisateurs accédant simultanément à ces tableaux de base et les plus importants et que quelques-uns d'entre eux essaient de faire du tableau de bord tandis que le reste essaie de travailler… eh bien… Oubliez ça ! Allez vous acheter un café ou abonnez-vous à des cours de Zen.
Mesurer l'écart de performance
Beaucoup de nos clients, y compris des départements informatiques, d'autres partenaires Odoo et des développeurs indépendants, nous ont demandé d'optimiser leurs implémentations car le système ralentissait. J'ai passé un certain temps à jouer avec ce qui suit afin de vous donner un véritable aperçu de l'optimisation Big data Ddoo. Mon kit de test se composait de ce qui suit :
-
1 XEON E5 – 6 cœurs CPU 2Ghz
-
8 Go de RAM
-
Disque dur SSD 256 Go
-
Ubuntu 16.04
-
PostgreSQL 9.5
-
Test effectué avec et sans PgBouncer
-
Données factices générées pour l'occasion dans les tables account_move/ account_move_line
Voici les résultats de ma mesure des éléments suivants :
-
Sélection de tous les éléments du journal de tous les journaux
-
Regroupé par période
-
Date effective supérieure à…
-
Date effective inférieure à…
-
Avec le total calculé SOMME pour les colonnes Crédit / Débit en bas
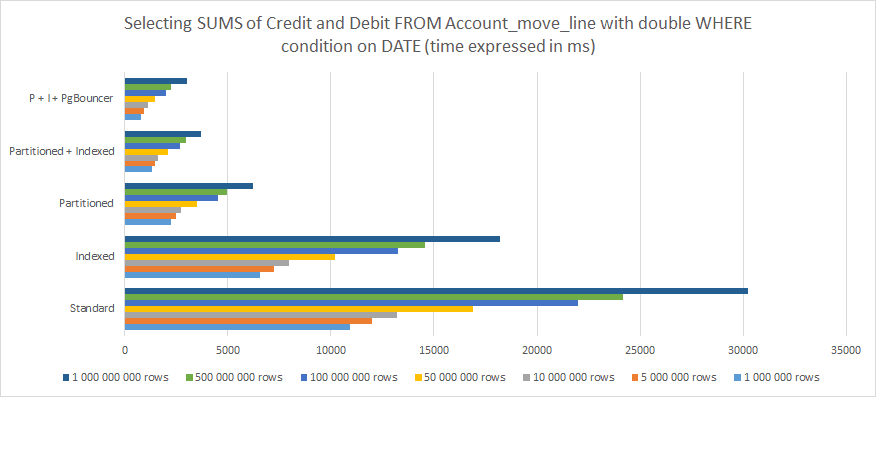
À partir de ce qui précède, on peut clairement comprendre que :
-
Indexation aide mais n'est pas suffisant à long terme
-
Partitionnement fonctionne beaucoup mieux
-
Combinaison de Partitionnement et d'Indexation fonctionne encore mieux
-
Combiner la partition et l'indexation et les associer à PgBouncer donne les meilleurs résultats.
Pour 1 000 000 000 de lignes, la différence de performance entre une structure PostgreSQL Odoo standard prête à l'emploi et optimisée avec partitionnement, indexation et PgBouncer passe de 30 000 ms (30 secondes) à moins de 3 000 ms (3 secondes) . Toutefois, gardez à l'esprit qu'il ne s'agit que d'une demande d'un seul utilisateur. Mettez cela en perspective avec 30 utilisateurs concurrents ou plus et vous comprendrez que c'est la différence entre un système qui fonctionne et celui qui expire systématiquement et provoque des erreurs jusqu'à s'écraser finalement.
Si vous êtes sceptique quant aux données collectées ci-dessus pour l'optimisation Big Data Odoo, veuillez jeter un œil à ce post : PostgreSQL : Table partitionnée vs Table non partitionnée . Cela n'est pas dédié à Odoo et traite des tables plus simples à l'intérieur de PostgreSQL, mais l'approche est très directe et précise… et les conclusions sont assez identiques.

Recherchez-vous à optimiser un grand volume de données dans votre système ?
Mise en œuvre de votre stratégie d'optimisation des grandes données Odoo
Si vous lisez ce post, cela signifie que vous envisagez soit de fournir des solutions de big data avec Odoo ou PostgreSQL comme base, soit que vous éprouvez déjà de la lenteur. Cependant, sachez que la lenteur peut provenir de différentes raisons :
-
Vous avez laissé votre PostgreSQL configuré par défaut. Il y a beaucoup à faire à ce sujet afin d'exploiter le véritable potentiel de votre serveur/cluster PostgreSQL et les paramètres par défaut doivent définitivement être remplacés par une stratégie appropriée de ressources et d'utilisation.
-
Vous avez un problème de mise en file d'attente de session et d'authentification HBA ou les deux : apprenez à utiliser PgBouncer.
Si aucun de ces deux ne s'applique à votre cas, alors vous devez probablement envisager l'indexation et la partition en effet et mes recommandations sont les suivantes :
-
Attention, l'indexation peut devenir coûteuse en ressources, surtout si vous manipulez des valeurs de chaîne.
-
Mettre l'indexation partout est une MAUVAISE approche. Ne le mettez que là où vous savez que l'ORM et vos modules sont susceptibles d'envoyer et de récupérer des valeurs.
-
Définissez une stratégie de partitionnement dès le départ et ne attendez pas que vos tables deviennent énormes. Vous CONNAISSEZ le profil de votre client, le chiffre d'affaires, les utilisateurs et cela DOIT être anticipé.
-
Votre stratégie de partitionnement doit suivre les orientations de croissance des données. Chaque client est différent. C'est toujours un processus "par cas".
-
Appliquez une logique de table de partitionnement qui suit la logique des déclencheurs.
-
Attention aux règles de déclenchement mal définies qui peuvent causer des chevauchements de données ou des boucles infinies.
-
Les règles de partitionnement fonctionnent… mais d'expérience, les déclencheurs fonctionnent juste MIEUX avec Odoo. Donc, contentez-vous des déclencheurs.
-
Si votre version de PostgreSQL est 11 ou supérieure, je vous recommande fortement de recourir à l'héritage de partition.
-
Soyez doux avec les Triggers. Si vous avez besoin de complexité, mettez-la dans la fonction à la place.
-
Étendez vos partitions enfants selon le modèle Odoo ou Data.
-
Utilisez des exclusions de contrainte pour optimiser la vitesse de votre requête. Pour ce faire, rappelez-vous de structurer votre partitionnement selon ces exclusions.
Si vous avez déjà un système lent et que vous devez resegmenter vos données à travers un processus de partitionnement d'optimisation Odoo Big data, vous devez suivre les directives ci-dessous :
-
Appliquez aussi les recommandations ci-dessus.
-
N'oubliez pas qu'Odoo ne sait pas que vous modifiez la structure des données à l'intérieur de PostgreSQL. Bien le faire implique que vous préserviez tous les noms des tables parents, colonnes, formats de données et contraintes inter-table.
-
Vérifiez vos données avant et après le resegmentation/partitionnement. OUI, c'est basique... mais vous devez être sûr que tout est là.
-
N'oubliez pas de viser l'avenir également. Diviser les données par année pour les données passées mais ne pas les diviser pour les années à venir est une GRANDE erreur. N'oubliez pas que PostgreSQL ira aussi lentement que les requêtes les plus lentes de toutes. Donc, si vous envisagez de bien diviser les 5 dernières années complètes et ensuite de laisser un gros désordre comme table active pour tout le reste qui continue à croître, vous n'avez absolument rien résolu... et vous ne faites qu'encombrer les choses. La performance sera dégradée tout autant.
Port Cities - équipe mondiale avec une expertise en optimisation des Big Data d'Odoo
Si vous pensez que l'optimisation des Big Data est un sujet trop spécialisé pour votre équipe interne, car une seule erreur peut compromettre l'intégrité des données, vous devriez envisager de faire intégrer cela par une équipe qui a de l'expérience à la fois en Odoo et en PostgreSQL. Port Cities dispose d'une équipe mondiale de plus de 80 développeurs internes prêts à vous aider avec votre optimisation des Big Data .
Contactez-nous pour plus d'informations sur la façon d'optimiser vos données et d'améliorer les performances de votre système à mesure que votre entreprise se développe.